What Happens When AI Agents Talk to Each Other
I've been watching a quiet shift happen over the last six months. The question used to be "how do I get my AI agent to do something useful?" Now it's "how do I get my AI agents to work together?"
The difference matters more than it sounds.
The problem with one agent doing everything
Most people start with a single agent. It reads your email, checks your calendar, maybe posts to Slack. And for a while, that works fine. Then you ask it to do something that involves judgment in two domains at once, and things get weird.
"Research this company, cross-reference against our CRM, draft an outreach email, and schedule a follow-up." That's four distinct tasks requiring four distinct contexts. One agent juggling all of that is like asking a single person to be a researcher, a salesperson, a copywriter, and an executive assistant simultaneously. Possible, but the quality drops with each hat.
This is why multi-agent setups exist. You split the work. A research agent handles the company lookup. A data agent queries the CRM. A writing agent drafts the email. A scheduling agent finds the time slot. Each one does its thing well because it only does one thing.
But here's the question nobody was asking until recently: how do these agents actually talk to each other?
The messy reality of agent communication
For most of 2024 and 2025, the answer was: badly. You'd have a parent orchestrator calling child agents through API wrappers, passing JSON blobs back and forth, hoping the output format of one agent matched what the next one expected.
If you've built any multi-agent system, you know the pain. Agent A returns a response with "company_name" as a field. Agent B expects "companyName". Everything breaks. You write adapters. Then Agent A gets updated and changes its output format. Your adapters break. You write more adapters.
It felt like early web development before people agreed on REST conventions. Everyone building their own thing, nothing fitting together.
Enter the protocols: MCP and A2A
Two protocols changed the game in 2025-2026, and they solve different halves of the problem.
MCP (Model Context Protocol) handles agent-to-tool communication. It's how an agent discovers and uses tools: "here's a search API, here's a database, here's a calendar." Think of it as USB-C for AI agents. Anthropic released it, and within months the ecosystem had over a thousand MCP servers. If you've used OpenClaw, you've used MCP whether you realized it or not.
A2A (Agent-to-Agent protocol) handles something different: agent-to-agent communication. Google published the spec in early 2025, and it answers the question of how Agent A finds Agent B, figures out what it can do, and sends it a task with structured expectations about what comes back.
The two protocols are complementary. MCP connects agents to tools. A2A connects agents to each other. Together, they make multi-agent systems that don't require a single team to have built everything.
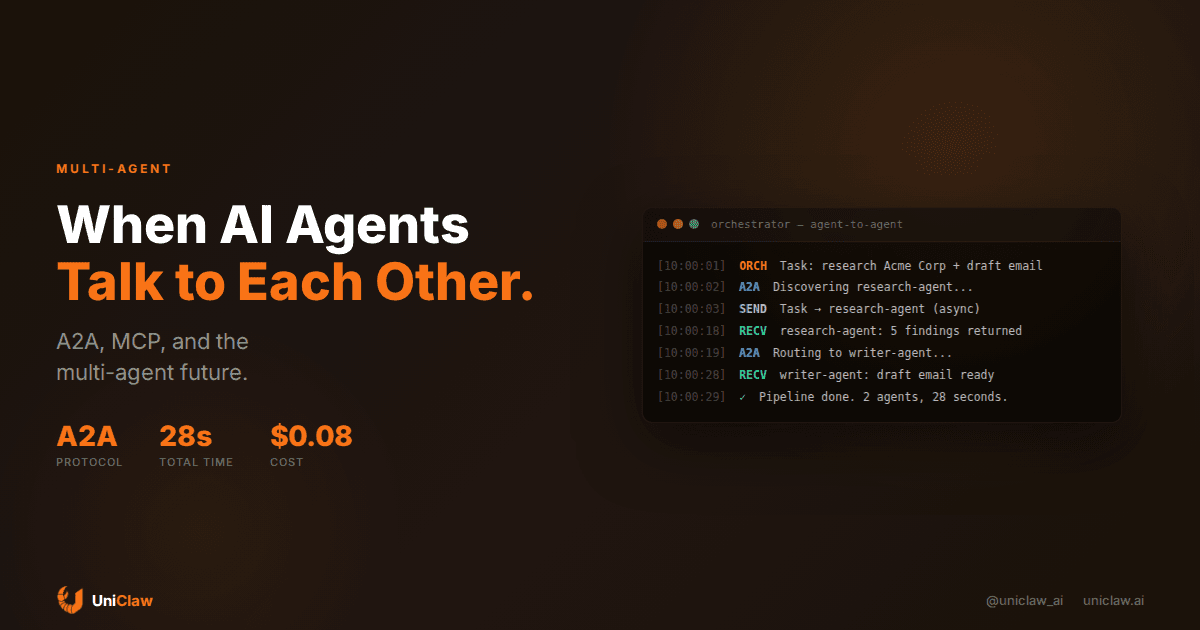
What agent-to-agent communication actually looks like
Let's make this concrete. Say you have a workflow: "Monitor Hacker News for mentions of our product and summarize the sentiment weekly."
Without A2A, you build one big agent that scrapes HN, analyzes sentiment, and writes summaries. Or you hardcode a pipeline where script A passes data to script B.
With A2A, it works more like this:
- Your orchestrator agent discovers a "web monitoring" agent through its agent card (a JSON file that describes the agent's capabilities, like a business card)
- It sends a task: "Monitor these URLs for mentions of [product name]"
- The monitoring agent accepts the task and works asynchronously
- When it has results, it streams them back or sends a completion message
- The orchestrator routes those results to a "sentiment analysis" agent using the same pattern
- The analysis agent returns structured sentiment data
- A "report writer" agent turns it into a weekly summary
Each agent is independently deployed, potentially built by different teams, possibly running on different infrastructure. The protocol handles the handshake, task delegation, status updates, and result formatting.
Why this matters for people running real agents
If you're running a single agent on UniClaw right now, you might wonder why any of this matters to you. Fair question.
Here's the practical angle: the agent ecosystem is getting specialized. Instead of building one mega-agent that's mediocre at everything, you're going to see agents that are exceptional at narrow tasks. A research agent that's incredibly good at finding and summarizing information. A coding agent that actually writes production-quality code. A customer service agent that handles support tickets with accuracy and real empathy.
Your personal agent becomes the coordinator. It knows your preferences, your schedule, your context. When it needs something done, it delegates to a specialist agent, gets the result, and brings it back to you.
OpenClaw already supports this pattern through sub-agents. You can spawn isolated sessions that run their own tasks and report back. The architecture is there. As A2A matures, the pool of agents your agent can call on gets much bigger.
The trust problem nobody talks about
Here's where I get nervous, though.
When your agent calls another agent, you're extending trust. Your agent might send context about your work, your preferences, your data to an agent you didn't build, running on infrastructure you don't control.
MCP has this problem with tools too, but at least tools are relatively simple and their behavior is predictable. An API that searches the web is going to search the web. An agent that "processes your data" could do anything.
The A2A spec includes some provisions for this. Agent cards describe capabilities and expected inputs/outputs. There's authentication built in. But the fundamental question doesn't go away: how do you audit what happened when Agent B processed the data your Agent A sent?
For now, the safest approach is what OpenClaw does by default: run your agents on your own infrastructure, keep data local where possible, and only send the minimum necessary context when delegating to external agents. Self-hosted agents on dedicated machines give you an actual audit trail. You can see exactly what your agent sent, what it received, and what it did with the response.
This is one of those areas where running your agent on a dedicated cloud machine instead of a shared API endpoint makes a real difference. Your logs are your logs. Your data stays on your machine.
What's working right now
Multi-agent setups are already practical for a few patterns:
Research and analysis. Spawn a research sub-agent, let it dig through sources, get back a summary. This works well because the input is a question and the output is text. Low coordination overhead.
Code review and generation. Your main agent hands off a coding task to a specialized coding agent (like Codex or Claude Code). The coding agent works in a sandboxed environment, and your main agent reviews the output. OpenClaw supports this through ACP (Agent Coding Protocol) sessions.
Monitoring and alerts. Background agents that watch for conditions (price changes, website status, new mentions) and notify your primary agent when something happens. These are mostly independent and only communicate results.
Data processing pipelines. Agent A fetches raw data, Agent B cleans it, Agent C analyzes it. The output of one feeds directly into the next. This is the simplest form of agent coordination and works reliably today.
What's still broken
Complex negotiation between agents. When two agents need to go back and forth to reach a decision, things get flaky. The protocols support multi-turn conversations, but in practice, agents are bad at knowing when they have enough information to proceed and when they need to ask for more.
Error recovery. When Agent B fails halfway through a task, what happens? Does Agent A retry? Does it try Agent C instead? Does it give up and ask the human? Most multi-agent systems handle the happy path well and fall apart on errors.
Cost and latency. Every agent-to-agent call adds latency and token costs. A simple task that one agent handles in 5 seconds might take 30 seconds across three agents because of the communication overhead. Sometimes a single agent doing everything imperfectly is better than three agents doing it well but slowly.
Practical advice if you're building this
If you want to start with multi-agent setups, here's what I'd actually recommend:
Start with sub-agents, not peer agents. Use your main agent as the coordinator and spawn specialized agents for specific tasks. OpenClaw's sub-agent spawning does exactly this. You don't need A2A to start getting value from multiple agents working together.
Keep the communication surface small. The fewer things agents need to pass between each other, the fewer things can go wrong. Clear, simple task descriptions in, structured results out.
Use dedicated machines. When you're running multiple agents, resource contention becomes real. Each agent should have its own environment, its own memory, its own workspace. UniClaw gives you a dedicated VM per agent for exactly this reason.
Build in human checkpoints. Don't let Agent A delegate to Agent B delegate to Agent C without any human in the loop. At minimum, have your primary agent summarize what happened and ask for confirmation before acting on multi-agent results.
Log everything. When something goes wrong in a multi-agent pipeline (and it will), you need to trace what each agent sent and received. Without logs, debugging is guesswork.
Where this is going
I think we're about 12-18 months away from agent-to-agent communication being as routine as API calls. The protocols are maturing. The tooling is catching up. And the benefits are real enough that people will put up with some rough edges.
The end state looks something like this: you have a personal agent that knows you and your work. When it needs help, it reaches out to specialist agents the same way you'd message a colleague. "Hey, can you analyze this data?" "Sure, here's what I found." Clean, fast, and with a full paper trail.
We're not there yet. But the pieces are falling into place, and the people building agents today are going to have a head start when it clicks.
If you're running an agent on UniClaw, you're already set up for this future. Dedicated machine, MCP tools, sub-agent spawning, full logging. The multi-agent world is coming, and your agent will be ready for it.
Ready to deploy your own AI agent?
Get Started with UniClaw